Torq Introduction
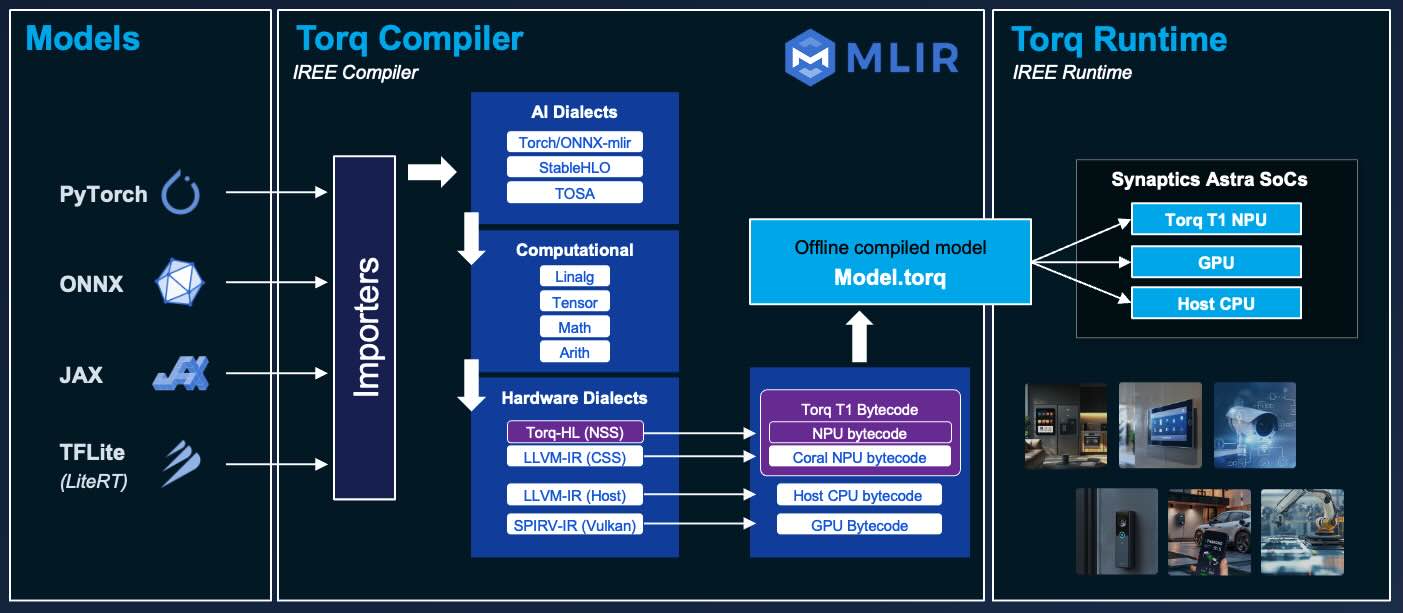
The Torq Edge AI Platform enables execution of diverse neural networks, efficiently utilizing NPU acceleration. The Torq tools and compiler allow you to convert a model from its original format to an representation optimized for the targeted Torq NPU. In this tutorial, you will learn how to bring your own model, optimize it for the Synaptics Astra SL261x processors, and test model inference speeds.
Torq is based on the open-source IREE/MLIR compiler and runtime. You can write applications in C/C++ or Python and leverage Torq NPU acceleration. To learn more about Torq, visit the Torq Compiler User Manual
Check out the User Section for additional information on compiling and running models.
For advanced developers, check out the Developer Section to learn how to contribute to the industry-shifting effort to democratise edge AI tools.
Torq supports running models converted from multiple frameworks including TensorFlow, ONNX, PyTorch and JAX.
Models are converted into a static representation that is optimized to run on a Torq NPU. At runtime, the models are executed with the Torq / IREE runtime engine, which is a lightweight engine for executing pre-compiled models.
Compiling your model ahead of time into a optimized static representation is much more efficient than other approaches that translate models at runtime. Compiling gives you more control, better optimization, and more predictable performance.