 Context-aware computing delivers
Context-aware computing delivers
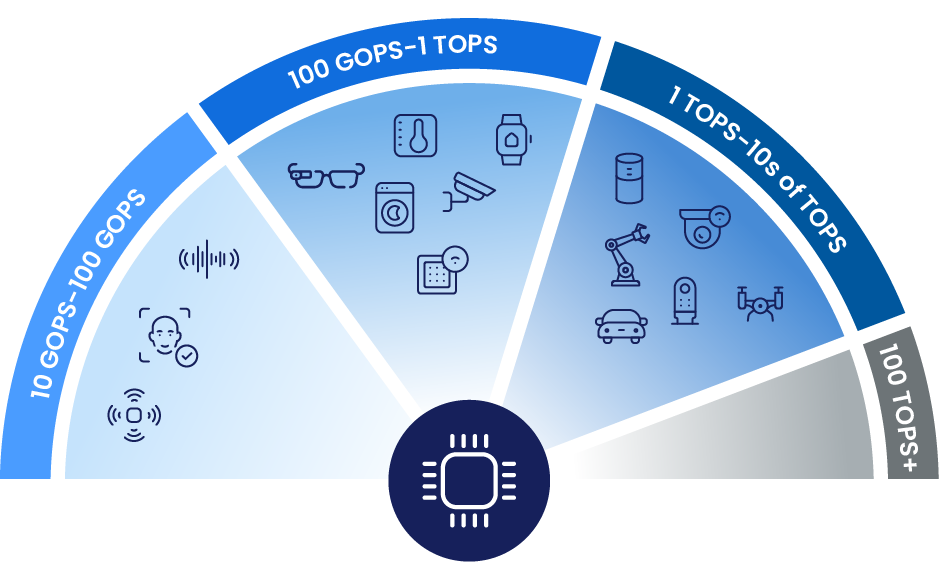
intelligence at various power levels
Synaptics Astra platforms enable efficient on-device AI with NPUs, GPUs, and scalable MPU/MCU compute. Developers can optimize for different power and performance needs, with support for modern models. Open software, flexible tools, and ready-to-use peripherals help speed up development and deployment.
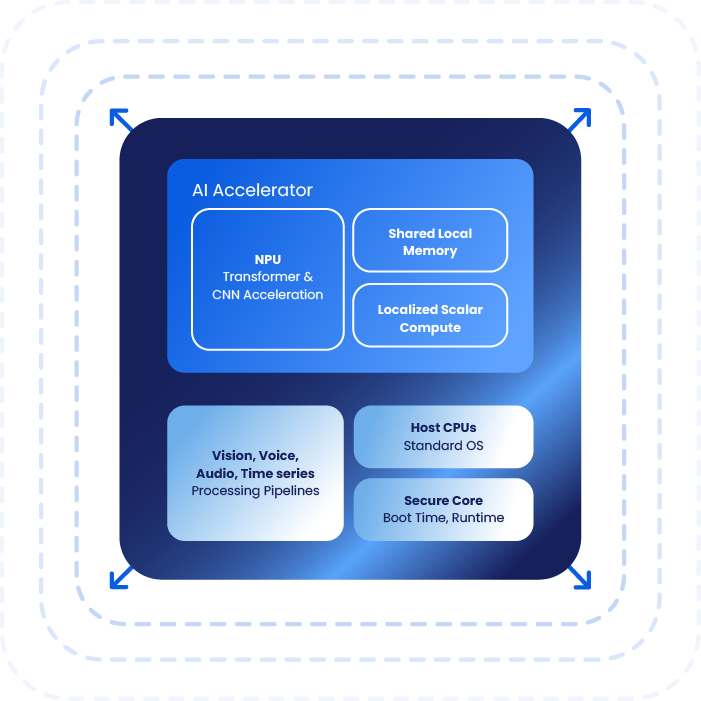
 Scalable Future-ready AI architecture
Scalable Future-ready AI architecture
Traditional NPUs are efficient but limited to fixed operations. Newer designs like Synaptics Torq with Coral NPU add flexibility through software updates, enabling support for newer models without hardware changes. This extends device life and supports evolving AI workloads.
 Quantization and optimization
Quantization and optimization
Model quantization is essential for edge performance. Synaptics supports INT8, INT4, mixed precision, and ultra-low 1.58-bit to balance accuracy and efficiency across different models and use cases.
 Edge AI efficiency
Edge AI efficiency
Hardware-aware tools map models to NPU and GPU resources to improve speed. Features like mixed precision and per-channel quantization help balance performance, accuracy, and memory.
 Models ready to go
Models ready to go
Get your project started in minutes with optimized models for Synaptics Astra.
 Bring your own model
Bring your own model
Have a different model you'd like to bring? Synaptics provides multiple compiler options for targeting supported NPUs, depending on your device family and workflow.

- Torq™ Compiler
- SyNAP® Compiler
Torq is a next-generation compiler targeting the latest generation Synaptics Astra platforms. It is built on open compiler infrastructure (MLIR and IREE), enabling flexibility for evolving model architectures and execution backends. Torq is recommended for upcoming devices and workflows that require extensibility and support for newer operator sets. A typical workflow:
$ iree-import-tflite example.tflite -o model.tosa
$ torq-compile model.tosa -o model.vmfb --torq-hw={$CHIP_MODEL}
The SyNAP compiler is a production-proven toolchain for Astra SL1600-Series. It is based on Apache TVM and optimized for efficient deployment on existing hardware. SyNAP provides a stable and streamlined path to convert and deploy models across supported platforms. A typical workflow:
$ synap convert --target {$CHIP_MODEL} --model example.tflite
Get started in minutes

Intro to Edge AI
Learn about running AI models directly on embedded devices in real-time.
Learn more →

Get Started with SL-Series
Get started with quick tutorials and embark your Edge AI journey with Machina Dev Kits.
Learn more →

Evaluate Models for SR-Series
Evaluate your models for High-Performance SR-Series AI MCUs.
Learn more →
Reference Docs
🤖 Torq AI Platform
Explore the Torq toolchain for newer Astra-Series products and next-generation NPU workflows.
Read more →🛠️ SyNAP AI Toolkit
Deep dive into the SyNAP toolkit for building and deploying AI applications on Astra SL1600.
Read more →💻 Astra SL SDK
Get started with the Synaptics Astra SL-Series Linux SDK documentation.
Read more →