Bring Your Own Model
The Torq Edge AI Platform enables execution of diverse neural networks, efficiently utilizing NPU acceleration. The Torq tools and compiler allow you to convert a model from its original format to an representation optimized for the targeted Torq NPU. In this tutorial, you will learn how to bring your own model, optimize it for the Synaptics Astra SL261x processors, and test model inference speeds.
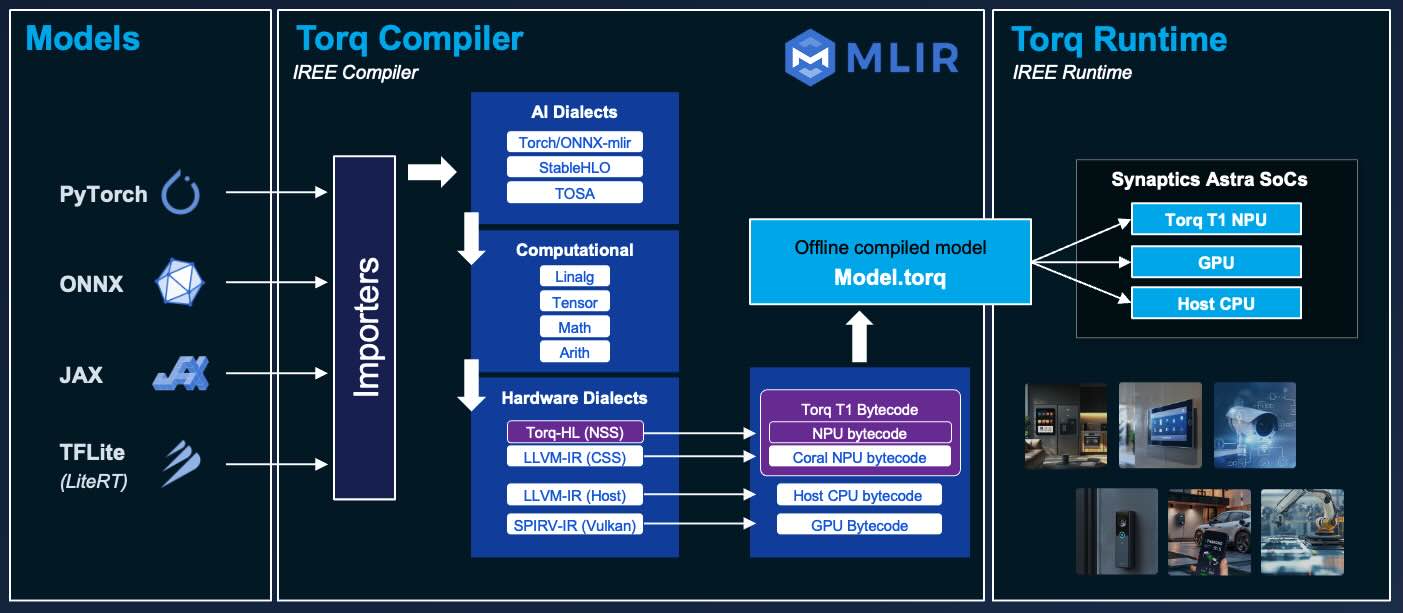
Torq is based on the open-source IREE/MLIR compiler and runtime. You can write applications in C/C++ or Python and leverage Torq NPU acceleration. To learn more about Torq, visit the Torq Compiler User Manual
Check out the User Section for additional information on compiling and running models.
For advanced developers, check out the Developer Section to learn how to contribute to the industry-shifting effort to democratise edge AI tools.
Torq supports running models converted from multiple frameworks including TensorFlow, ONNX, PyTorch and JAX.
Models are converted into a static representation that is optimized to run on a Torq NPU. At runtime, the models are executed with the Torq / IREE runtime engine, which is a lightweight engine for executing pre-compiled models.
Compiling your model ahead of time into a optimized static representation is much more efficient than other approaches that translate models at runtime. Compiling gives you more control, better optimization, and more predictable performance.
Overview
Environment setup
Synaptics provides an environment package which includes the necessary Torq compiler tools and dependencies.
To ease setup and maintain an isolated environment, Synaptics provides a prebuilt Docker image on the GitHub Container Registry.
Install Docker
Sign into the GitHub Container Registry
docker login ghcr.io
You will need to have a GitHub account and a GitHub personal access token.
Download a model
In this tutorial, you will convert a tflite model and compile it into the Torq bytecode file format.
Download the mobilenet_v2 TensorFlow Lite model from Kaggle.
Extract the file with any compatible tool, such as:
tar -xvzf mobilenet-v2-tflite-1-0-224-quantized-v1.tar.gz
For simplicity, rename the file to mobilenetv2.tflite.
Run the Docker container
Create and run a Docker container
docker run --rm -it -v $(pwd):$(pwd) -w $(pwd) -u $(id -u):$(id -g) ghcr.io/synaptics-torq/torq-compiler/compiler:main
Converting a model into a MLIR dialect
Before compling, the model needs to be expressed in a MLIR-supported dialect.
In this tutorial, we will focus on a commonly used dialect called Tensor Operator Set Architecture (TOSA).
MLIR files in TOSA dialect can be in binary format (.tosa) or text format (.mlir).
With the Docker container running, execute this command.
iree-import-tflite mobilenetv2.tflite -o mobilenetv2.tosa
If you are using macOS on Apple Silicon, you may encounter an invalid instruction error with the iree-import-tflite tool referenced in this tutorial.
This can be resolved by building a docker image with the linux/arm64 platform type. See steps below to build your own Docker image
Compile the model into the Torq bytecode format
Compile the model with this command:
torq-compile mobilenetv2.tosa -o mobilenetv2.vmfb \
--torq-convert-dtypes \
--torq-enable-torq-hl-tiling \
--torq-enable-transpose-optimization \
--torq-convert-io-dtype \
--torq-hw=SL2610
--torq-convert-dtypes and --torq-convert-io-dtype ensure no unsupported datatypes remain in the model, so all operations can run on the NPU.
--torq-enable-torq-hl-tiling disables hardware tiling for stability. This can be enabled later.
--torq-enable-transpose-optimization converts data dimensions into NCHW, which aligns best with the NPU
The Torq compiler has many options. To get a full list, type this command.
torq-compile -h | grep <flag>
The output of the compiler will be a mobilenetv2.vmfb file, which is a Virtual Machine FlatBuffer (VMFB) file storing the Torq bytecode.
Exit the Docker container
exit
Upload model to the Astra SL2610 board
You can now upload it to your Machina board in a terminal with:
adb push mobilenetv2.vmfb /home/root/
Test the model
On your dev machine, open an ADB shell to Astra:
adb shell
In the command prompt for the Astra, run the model with dummy data.
cd /home/root
iree-run-module --device=torq --module=mobilenetv2.vmfb --function=main --input="1x224x224x3xi8=1”
You will see this, which indicates that the model ran correctly.
1x1000xi8=[-128 -128 -128 -128 -128 -128 -128 -128 -128 -128 …
Congratulations
You've just imported a model from Kaggle, optimized it for Torq NPU, and ran it on Synaptics Astra SL2619!
Check out the quick guide on image classification to learn how to run it.
Additional Information
If you are using macOS on Apple Silicon, you may encounter an invalid instruction error with the iree-import-tflite tool referenced in this tutorial.
Build a docker image with the linux/arm64 platform type. Follow these steps.
- Download the latest release package.
- Extract the files.
tar -xvzf release.tar.gz
cd release
- Build a docker image with the
linux/arm64platform type.
docker build --platform linux/arm64 -t synaptics-torq/torq-compiler/compiler-arm64:latest .
- Create and run a container for model conversion
docker run --rm --platform linux/arm64 -it -v $(pwd):$(pwd) -w $(pwd) -u $(id -u):$(id -g) synaptics-torq/torq-compiler/compiler-arm64
Use this for running the iree-import-tflite command only.