Object Detection
Object Detection is a technique that helps computers find and label multiple objects in an image, like detecting people, cars, or animals in a photo. Whereas Image Classification associates a single label with a whole image, Object Detection uses bounding boxes around individual objects in an image. This makes tracking the position and behavior of objects in a scene possible.
YOLO (You Only Look Once) models
YOLO model, which stands for "You Only Look Once," is a type of computer vision model used for real-time object detection, where it identifies and locates objects within an image by processing it in a single pass, meaning it only needs to "look" at the image once to detect objects within it, making it very fast compared to methods that require multiple passes.
YOLO was originally created by Joseph Redmon in 2016, later transitioning to a community model with significant contributions by Ultralytics, their latest version being YOLO11.
 Source: Ultralytics
Source: Ultralytics
Run Object Detection on Astra
If you haven't yet setup your board and installed the examples, please refer to the quick start.
The Quick guide is compatible with all Machina SL2600-Series kits with OOBE image with pip and python pre-installed
To run the example on Astra, first you need to run through the Prerequisites which downloads the GitHub Examples Repo on your board.
Set up your environment
If you haven't done so already, setup your environment.
Clone our Examples GitHub repository and Navigate to the Repository Directory:
git clone https://github.com/synaptics-astra-demos/sl2610-examples
cd sl2610-examples
Set up your Python environment ensuring all required dependencies are installed within a virtual environment:
python3 -m venv .venv --system-site-packages
source .venv/bin/activate
pip install -r requirements.txt
Set up the display environment (required for visual output).
export XDG_RUNTIME_DIR=/var/run/user/0
export WAYLAND_DISPLAY=wayland-1
Object Detection on the edge
Run inference on single images
cd object_detection/
python3 object_detection.py \
--model yolov8_od.vmfb \
--image dog_bike_car.jpg \
--labels labels.json \
--device torq
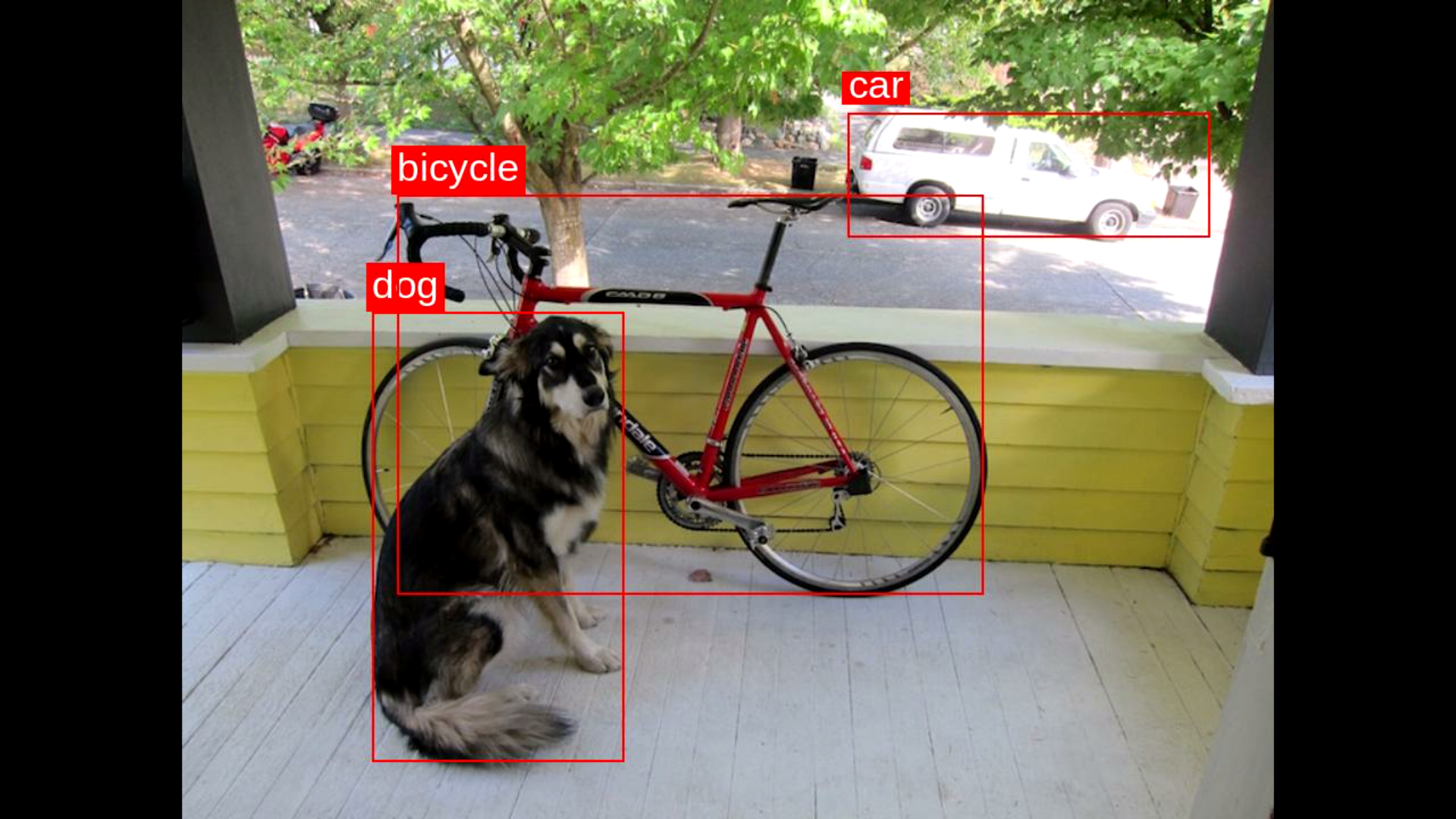
You should see a result in the form of:
Detections:
dog Conf: 0.9186 Box: [133 219 177 315]
car Conf: 0.5663 Box: [468 79 254 86]
bicycle Conf: 0.5663 Box: [151 137 412 280]
Run inference on camera or video input
Connect a USB Camera. Run inference on the camera input with this command.
python3 object_detection_video.py \
--model yolov8n_od.vmfb \
--camera-device auto \
--labels labels.json \
--device torq
Or run inference on a video file with this command.
python3 object_detection_video.py \
--model yolov8n_od.vmfb \
--video <your_video>.mp4 \
--labels labels.json \
--device torq
Additional options to try
--output, Output video file--json-results, Output JSON file for detections--camera-width, USB camera width--camera-height, USB camera height--camera-fps, USB camera frame rate--display, Display annotated frames live--display-sink, GStreamer video sink for live display
Offline? - Try offline dependencies installation
Python dependencies that are normally downloaded and installed with pip have been included for offline install. Install them with this command.
pip install --no-index --find-links=./wheelhouse -r requirements.txt
Python walkthrough
This Python example uses the Torq runtime python module which defines a class called VMFBInferenceRunner for loading the model and running inferences.
The runner object is created like this:
runner = torq_rt.VMFBInferenceRunner(
args.model,
device_uri=args.device,
function="main",
load_model_to_mem=True
)
Inference is started like this:
outputs = runner.infer([input_data])
Review the code ./object_detection/object_detection.py to learn more.
The Python-based Torq runtime leverages Python bindings to the C++ Torq / IREE runtime.
Up next, learn how to compile models with Torq
Check out the guide on how to Bring Your Own Model.