自带模型
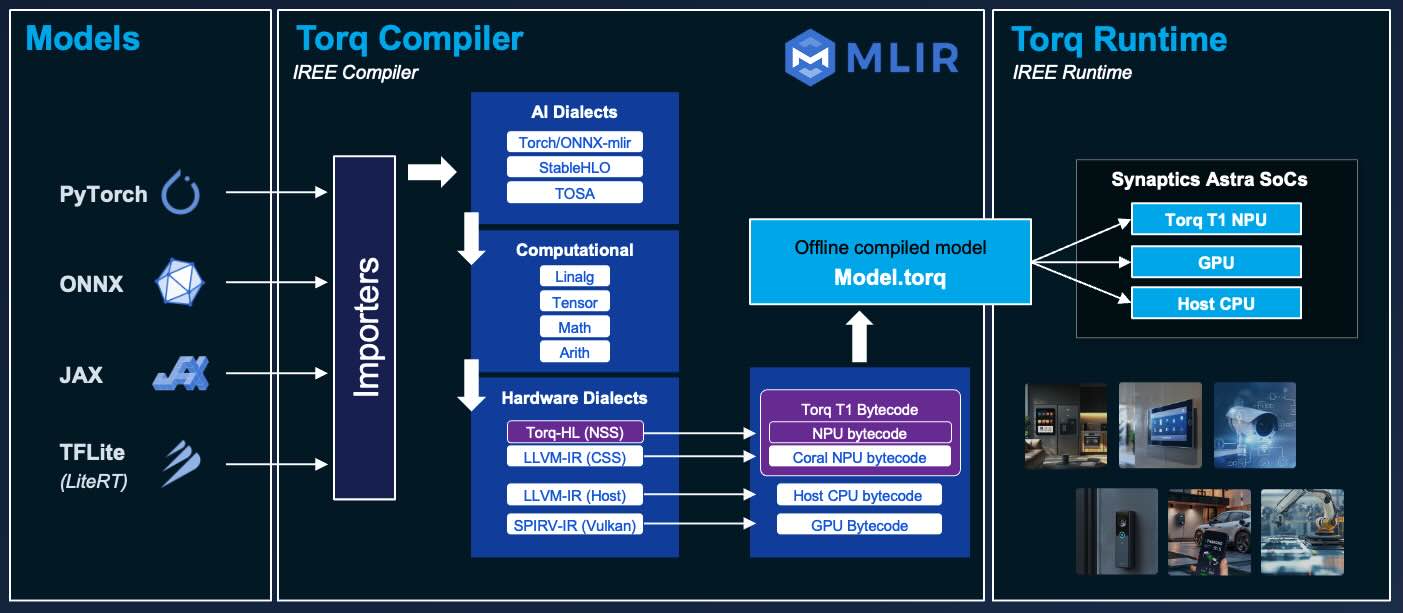
Torq 边缘 AI 平台支持执行多种神经网络,并高效利用 NPU 加速。Torq 工具链和编�译器可将模型从原始格式转换为针对目标 Torq NPU 优化的表示形式。在本教程中,您将学习如何自带模型,将其优化为适用于 Synaptics Astra SL261x 处理器,并测试模型推理速度。
Torq 基于开源的 IREE/MLIR 编译器和运行时。您可以使用 C/C++ 或 Python 编写应用程序并利用 Torq NPU 加速。更多关于 Torq 的信息,请访问 Torq 编译器用户手册
查看用户章节,获取关于编译和运行模型的更多信息。
对于进阶开发者,请查看开发者章节,了解如何参与推动边缘 AI 工具民主化的行业变革。
Torq 支持运行从多种框架转换的模型,包括 TensorFlow、ONNX、PyTorch 和 JAX。
模型会被转换为针对 Torq NPU 优化运行的静态表示。在运行时,模型通过 Torq / IREE 运行时引擎执行,这是一个轻量级的预编译模型执行引擎。
提前将模型编译为优化的静态表示,比运行时翻译模型的其他方式效率更高。编译让您拥有更多控制权、更好的优化效果和更可预测的性能。
概览
环境设置
Synaptics 提供了包含必要 Torq 编译器工具和依赖项的环境包。
为简化设置并维护隔离环境,Synaptics 在 GitHub Container Registry 上提供了预构建的 Docker 镜像。
安装 Docker
登录 GitHub Container Registry
docker login ghcr.io
您需要拥有 GitHub 账号和 GitHub 个人访问令牌。
下载模型
在本教程中,您将转换一个 tflite 模型,并将其编译为 Torq 字节码文件格式。
从 Kaggle 下载 mobilenet_v2 TensorFlow Lite 模型。
使用任何兼容工具解压文件,例如:
tar -xvzf mobilenet-v2-tflite-1-0-224-quantized-v1.tar.gz
为简化操作,将文件重命名为 mobilenetv2.tflite。
运行 Docker 容器
创建并运行 Docker 容器
docker run --rm -it -v $(pwd):$(pwd) -w $(pwd) -u $(id -u):$(id -g) ghcr.io/synaptics-torq/torq-compiler/compiler:main
将模型转换为 MLIR 方言
在编译之前,需要将模型表示为 MLIR 支持的方言。
在本教程中,我们将重点使用一种常用方言——张量算子集架构(TOSA)。
TOSA 方言的 MLIR 文件可以是二进制格式(.tosa)或文本格式(.mlir)。
在 Docker 容器运行状态下,执行此命令:
iree-import-tflite mobilenetv2.tflite -o mobilenetv2.tosa
如果您使用的是 Apple Silicon 的 macOS,在使用本教程中提及的 iree-import-tflite 工具时,可能会遇到 无效指令 错误。
可通过使用 linux/arm64 平台类型构建 Docker 镜像来解决。**请参见下方步骤**自行构建 Docker 镜像。
将模型编译为 Torq 字节码格式
使用以下命令编译模型:
torq-compile mobilenetv2.tosa -o mobilenetv2.vmfb \
--torq-convert-dtypes \
--torq-enable-torq-hl-tiling \
--torq-enable-transpose-optimization \
--torq-convert-io-dtype \
--torq-hw=SL2610
--torq-convert-dtypes 和 --torq-convert-io-dtype 确保模型中没有不支持的数据类型,使所有操作都能在 NPU 上运行。
--torq-enable-torq-hl-tiling 为稳定性禁用硬件平铺,稍后可启用此功能。
--torq-enable-transpose-optimization 将数据维度转换为 NCHW,与 NPU 最为兼容。
Torq 编译器有很多选项。要获取完整列表,请输入此命令:
torq-compile -h | grep <flag>
编译器的输出将是一个 mobilenetv2.vmfb 文件,这是一个存储 Torq 字节码的 Virtual Machine FlatBuffer (VMFB) 文件。
退出 Docker 容器
exit
将模型上传到 Astra SL2610 开发板
现在您可以在终端中将其上传到 Machina 开发板:
adb push mobilenetv2.vmfb /home/root/
测试模型
在开发机器上,打开 ADB shell 连接到 Astra:
adb shell
在 Astra 的命令提示符中,使用虚拟数据运行模型:
cd /home/root
iree-run-module --device=torq --module=mobilenetv2.vmfb --function=main --input="1x224x224x3xi8=1"
您将看到以下输出,表明模型运行正确:
1x1000xi8=[-128 -128 -128 -128 -128 -128 -128 -128 -128 -128 …
恭喜
您已成功从 Kaggle 导入模型,针对 Torq NPU 进行优化,并在 Synaptics Astra SL2619 上运行!
查看图像分类快速指南,了解如何运行它。
附加信息
如果您使用的是 Apple Silicon 的 macOS,在使用本�教程中提及的 iree-import-tflite 工具时,可能会遇到 无效指令 错误。
使用 linux/arm64 平台类型构建 Docker 镜像,按照以下步骤操作:
- 下载最新的发布包。
- 解压文件:
tar -xvzf release.tar.gz
cd release
- 使用
linux/arm64平台类型构建 Docker 镜像:
docker build --platform linux/arm64 -t synaptics-torq/torq-compiler/compiler-arm64:latest .
- 创建并运行用于模型转换的容器:
docker run --rm --platform linux/arm64 -it -v $(pwd):$(pwd) -w $(pwd) -u $(id -u):$(id -g) synaptics-torq/torq-compiler/compiler-arm64
仅在运行 iree-import-tflite 命令时使用此容器。