 情境感知计算带来
情境感知计算带来
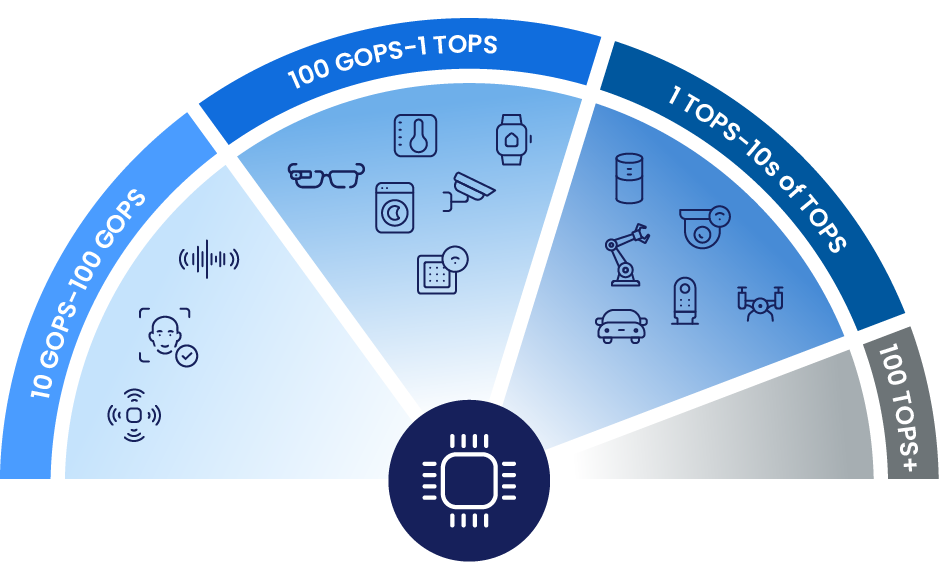
多种功耗级别的智能
Synaptics Astra 平台通过 NPU、GPU 以及可扩展的 MPU/MCU 计算实现高效的设备端 AI。开发者可根据功耗和性能需求进行优化,并支持现代模型。开放的软件、灵活的工具和即用型外设有助于加速开发和部署。
 可扩展的面向未来的 AI 架构
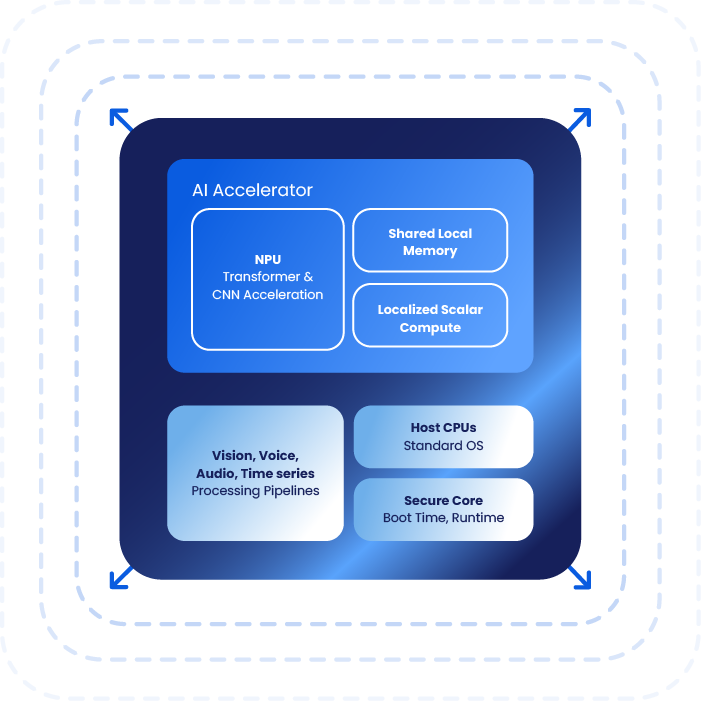
可扩展的面向未来的 AI 架构
传统 NPU 效率高,但受限于固定算子集。以 Synaptics Torq(搭载 Coral NPU)为代表的新型设计通过软件更新提升灵活性,无需更换硬件即可支持更新的模型。这延长了设备使用寿命,并支持不断演进的 AI 工作负载。
 量化与优化
量化与优化
模型量化是边缘性能的关键。Synaptics 支持 INT8、INT4、混合精度以及超低 1.58 位精度,在不同模型和使用场景中平衡精度与效率。
 高效赋能边缘AI
高效赋能边缘AI
具硬件感知的工具�将模型映射到 NPU 和 GPU 资源以提升速度。混合精度和逐通道量化等特性有助于在性能、精度和内存之间取得平衡。
 即刻启用模型
即刻启用模型
使用面向 Synaptics Astra 优化的模型,几分钟内即可启动你的项目
 使用自有模型
使用自有模型
有其他模型想要引入?Synaptics 提供多种编译器选项,可根据您的设备系列和工作流选择合适的 NPU 目标:

- Torq™ 编译器
- SyNAP® 编译器
Torq 是面向最新一代 Synaptics Astra 平台的下一代编译器,基于开放式编译器基础设施(MLIR 和 IREE)构建,能够灵活适配��不断演进的模型架构和执行后端。 Torq 推荐用于即将推出的设备及需要可扩展性和支持更新算子集的工作流。 典型工作流程:
$ iree-import-tflite example.tflite -o model.tosa
$ torq-compile model.tosa -o model.vmfb --torq-hw={$CHIP_MODEL}
SyNAP 编译器是面向 Astra SL1600 系列的经生产验证的工具链,基于 Apache TVM 构建,针对现有硬件的高效部署进行了优化。 SyNAP 提供稳定、简洁的路径,用于在支持的平台上转换和部署模型。 典型工作流程:
$ synap convert --target {$CHIP_MODEL} --model example.tflite



参考文档
关注我们

