AI 文本助手
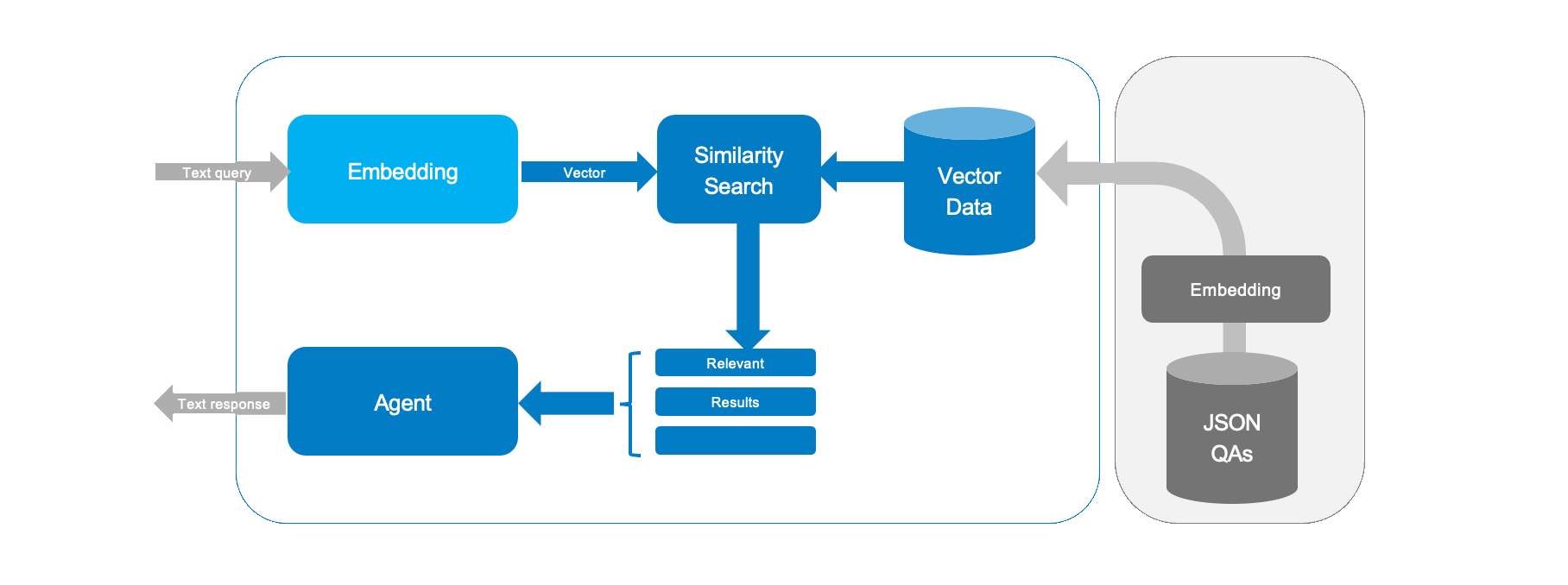
让我们构建一个 AI 助手,它使用来自之前的嵌入向量指南的嵌入和余弦相似度来从问答文件中选择最佳答案。
本快速指南适用于所有 SL16xx 开发板。虽然推理性能可能有所不同,但所有 Astra SL 系列处理器的步骤都相同。
我们的示例 assistant.text 执行以下操作:
- 从 JSON 文件
data/qa_pairs_zh.json加载问答对 - 创建文本嵌入向量
- 使用余弦相似度对答案进行排序
- 运行一个简单的循环来接收您的查询并给出数据集中最相关的回复
您可以使用以下命令查看数据库的内容:
cat assistant/data/qa_pairs.json
这个示例很小,但其��背后的原理可以扩展到支持更大的向量数据库 - 它被用于像 Perplexity.ai 这样的 LLM RAG 实现中。例如,数据来源之一可以是获取设备用户手册并将其转换为结构化的问答数据集,以实现一个简单的支持代理。
运行演示
要运行您的助手,在终端中输入:
python3 -m assistant.text assistant/data/qa_pairs_zh.json
您将看到类似这样的提示:
助手已就绪。输入您的问题(或输入 'exit' 退出):
>
输入您的问题,应用程序将显示最佳匹配和相似度分数。例如:
你是谁?
答案:我是一个运行在 Synaptics Astra SL 16 80 上的 AI 助手 相似度:0.98
尝试不同的问题格式,测试相似度分数的准确性。
深入解析
加载问答对
代码打开一个 JSON 文件并存储问答对。每对问答被合并成一个文本。然后使用这个文本来计算嵌入向量。
with open(qa_file, "r") as f:
self.qa_pairs = json.load(f)
texts = [pair["question"] + " " + pair["answer"] for pair in self.qa_pairs]
这段代码读取问答文件并为下一步准备文本。
生成嵌入向量
代码遍历每个文本并计算其嵌入向量。进度条显示工作完成的程度。
embeddings = []
for text in tqdm(texts, desc="计算嵌入向量"):
embeddings.append(self.embeddings.generate(text))
return np.array(embeddings)
每个文本都被转换为一个数字数组,有助于后续的比较。
使用余弦相似度进行搜索
这是关键函数。它为您的查询创建嵌入向量,并使用余弦相似度将其与存储的嵌入向量进行比较。
query_emb = self.embeddings.generate(query)
sims = cosine_similarity([query_emb], self.question_embeddings).flatten()
best_idx = np.argmax(sims)
以下是发生的过程:
- 查询被转换为嵌入向量
- 计算余弦相似度分数
- 最高分数告诉我们最佳匹配
多语言输入
在这个文本助手中,我们使用的是多语言版本的句子转换器 sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2!该模型经过训练,可以为不同语言中的相同文本输出相似的嵌入向量 - 您不需要指定输入语言。
尝试用另一种语言输入问题,它应该会匹配到相应的英文答案:
Was sind die Vorteile von Edge AI?
答案:Edge AI 更高效、更私密,且无需互联网即可工作。 相似度:0.892445476864138
Vielen dank
答案:不客气 相似度:0.8158796475751413
您可以翻译 ./assistant/data/qa_pairs.json 中的答案来创建不同语言的文本助手。
创建您自己的助手
自定义这种助手很简单 - 只需编辑 JSON 文件,添加您自己的问题和答案。这将让您看到新数据如何改变回复。
-
打开
./assistant/data/qa_pairs.json文件。 -
添加或更改条目。例如:
[
{
"question": "你叫什么名字?",
"answer": "我是一个友好的机器人。"
},
{
"question": "你好吗?",
"answer": "我很好,谢谢。"
},
{
"question": "讲个笑话",
"answer": "我还不知道任何笑话。"
}
] -
保存文件。
-
再次运行演示:
python3 -m assistant.text
您的助手现在将使用您自己的问答对。
结论
本指南向您展示了如何使用 Python 构建一个简单的 AI 文本助手。我们从 JSON 文件加载数据,计算文本嵌入向量,并使用余弦相似度来找到查询的最佳答案。
我们简单助手的一个限制是它只能提供静态的文本答案。增强功能的一种方法称为工具调用,它允许 AI 代理调用外部 API 或函数。我们将在下一个指南中了解工具调用。