目标检测
目标检测是一种帮助计算机在图像中查找和标记多个对象的技术,例如在照片中检测人物、汽车或动物。 与图像分类为整张图像分配单个标签不同,目标检测在图像中的各个对象周围使用边界框。这使得跟踪场景中对象的位置和行为成为可能。
YOLO(You Only Look Once)模型
YOLO 模型全称是"You Only Look Once"(只看一次),是一种用于实时目标检测的计算机视觉模型,它通过单次处理来识别和定位图像中的对象,这意味着它只需要"看"一次图像就能检测其中的对象,比需要多次处理的方法快得多。
YOLO 最初由 Joseph Redmon 在 2016 年创建,后来转变为社区模型,Ultralytics 做出了重要贡献,其最新版本是 YOLO11。
 来源:Ultralytics
来源:Ultralytics
在 Astra 上运行目标检测
本指南假设您已经熟悉 Astra 开发板的设置。如果还没有,请参考设置教程。
本快速指南适用于所有 Machina SL16xx 开发板,需要预装 pip 和 python 的 OOBE 镜像,并针对以下硬件进行了优化:
NPU 用于 SL1680 和 SL1640
GPU 用于 SL1620
要在 Astra 上运行示例,首先您需要完成先决条件,这将在您的开发板上下载 GitHub Examples 仓库。
完成先决条件后,将 USB 网络摄像头插入您的开发板,您可以使用以下命令拍照:
python -m utils.photo
现在您可以在拍摄的照片上运行推理:
python -m vision.object_detect 'out.jpg'
您应该看到如下形式的结果:
Starting Object Detection Stream.
{
"items": [
{
"confidence": 0.5889615416526794,
"class_index": 0,
"bounding_box": {
"origin": {
"x": 332,
"y": 145
},
"size": {
"x": 220,
"y": 245
}
},
"landmarks": []
}
]
}
Inference Time: 64 ms
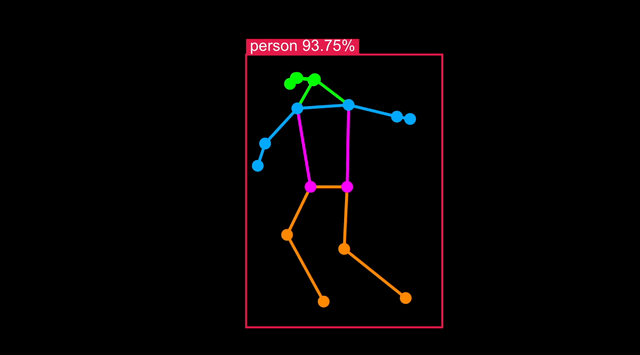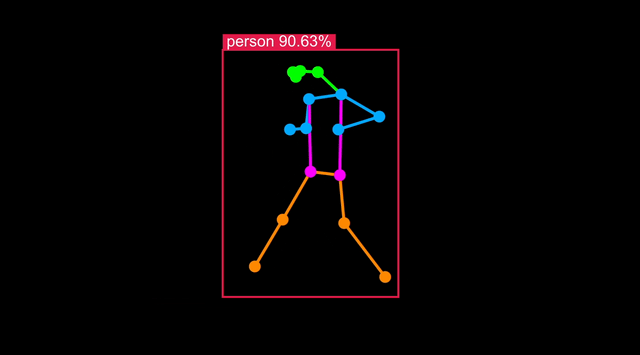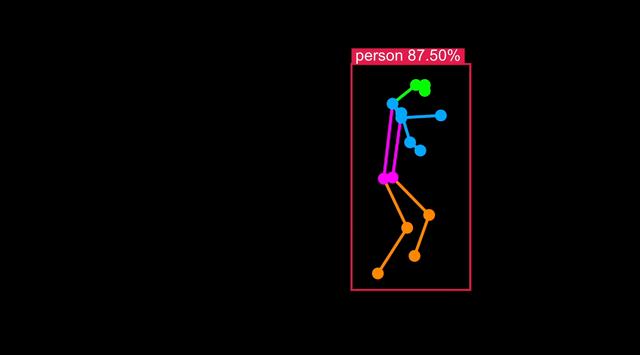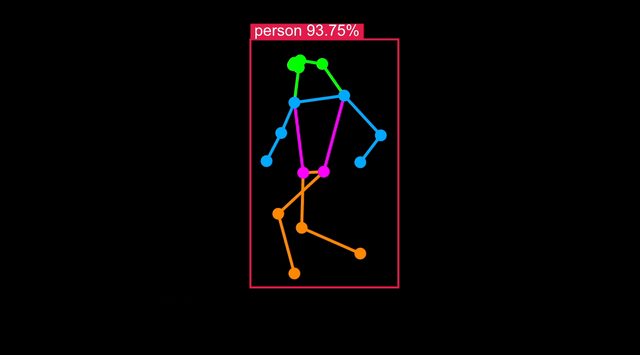
在 Astra 上运行人体姿态检测
人体姿态模型是目标检测的一种变体,在 COCO-Pose 等包含身体关键点的数据集上训练。
An example is also installed on your board. With a USB camera attached, you can run it with:
python -m vision.body_pose 'cam'
这将在开发板上启动应用程序服务器,在下一节中,您将连接浏览器到开发板并实时查看结果。
实时可视化结果
您可以连接到运行示例的 Astra Machina 开发板,并在开发板提供的网页中实时可视化结果。按照终端中的指示操作 - 您可以在开发机器上的网页浏览器中查看,或者在 Astra 上的 Chromium 中查看:
(.venv) root@sl1680:~/examples# python -m vision.body_pose 'cam'
Starting WebSocket server on port 6789
WebSocket server started.
Open your web browser at http://192.168.50.50
Python 代码详解
上面的 Python 示例使用 SynapRT 包直接从 Python 执行 NPU 加速推理。让我们通过 ./examples/video_steam.py 代码来了解它是如何工作的。
在 SynapRT GitHub 上了解更多关于 SynapRT 的信息。 示例开始时导入这个包:
from synapRT.pipelines import pipeline
接下来,我们实例化一个 SynapRT 管道,将 task 设置为 object-detection,model 设置为开发板上预装的优化 YOLOv8s 模型之一:
pipe = pipeline(
task="object-detection",
model="/usr/share/synap/models/object_detection/coco/model/yolov8s-640x384/model.synap",
profile=True,
handler=handle_results,
)
然后启动管道,将命令行参数作为输入:
pipe(sys.argv[1])
您可以找到关于为 Synaptics Astra NPU 编译 YOLO 的教程。