为边缘 NPU 编译 Ultralytics YOLO
在本示例中,您可以深入了解如何使用 SyNAP 工具包在 Synaptics Astra™ Machina™ 开发板上进行模型转换和优化。您可以从 Ultralytics 导出 YOLOv8 人体姿态模型,使用 SyNAP 执行针对 Synaptics Astra SL1680 中 NPU 的优化模型编译,在开发板上运行推理,并显示结果。
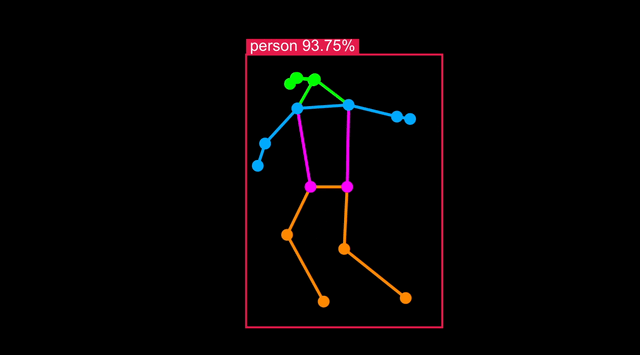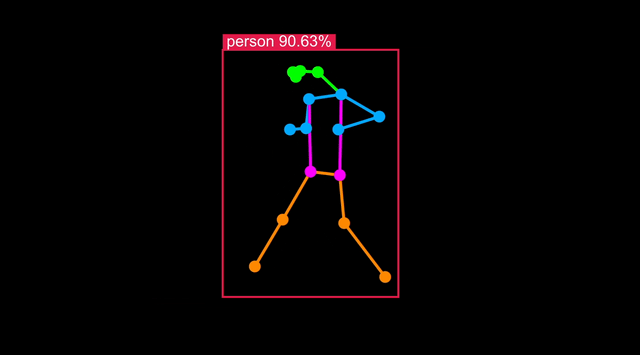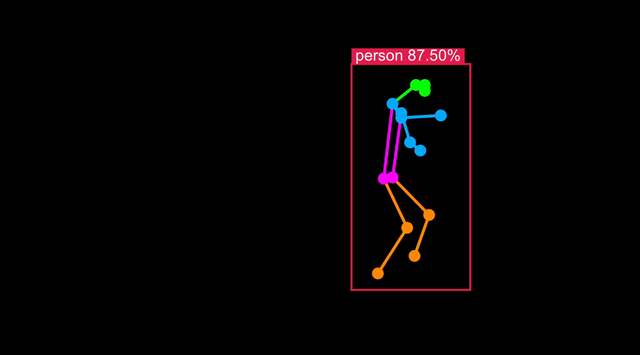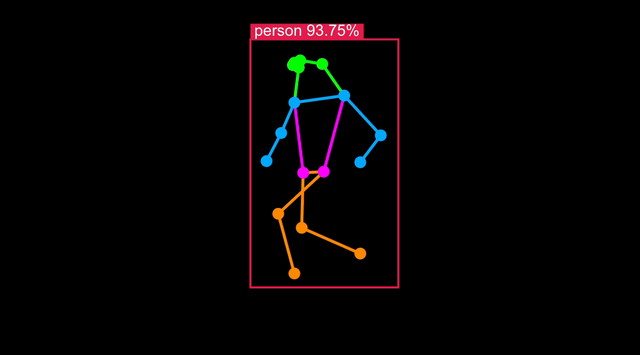
使用单个命令即可将模型优化为针对 Synaptics 处理器(SL1620、SL1640 或 SL1680)。
默认情况下,这将为 SL1680 和 SL1640 优化 NPU 模型,为 SL1620 优化 GPU 模型。
synap convert --target {$CHIP_MODEL} --model example.{$MODEL_FORMAT} --meta example.yaml
在 Google Colab 上准备模型
为了节省环境设置的时间,您可以在 Google Colab Notebook 上进行模型编译和优化,您可以立即运行:
打开用于边缘 NPU 的 Ultralytics YOLO 编译 Google Colab
在本地准备模型
导出 YOLOv8s 人体姿态模型
首先按照 Ultralytics 导出指南 获取 Ultralytics YOLOv8s 人体姿态模型的 ONNX 格式。
!pip install ultralytics
import ultralytics
ultralytics.checks()
!yolo export model=yolov8s-pose.pt format=onnx imgsz=352,640 opset=11
下载示例图像
!wget -q 'https://ultralytics.com/images/bus.jpg' -O bus.jpg
from IPython.display import Image
display(Image(filename='bus.jpg'))
安装 SyNAP 工具包
如果您在本地运行,需要安装 SyNAP 模型编译器。它接受来自 TensorFlow、TensorFlow Lite、ONNX 或 Caffe 的模型,并将它们编译为针对目标 Synaptics Astra 处理器上可用的 CPU、NPU 或 GPU 资源优化的格式。
以下是通过 Docker 安装 SyNAP 工具包 的步骤:安装 SyNAP 工具包
创建元文件 YAML
元��文件允许用户启用量化和其他优化。它提供细粒度的优化和计算委派功能,以进一步自定义和优化模型。在包含此 YAML 文件时,您需要指定 --meta 参数。
在本节中,我们将逐步解释如何为 YOLOv8s-pose 模型转换构建 YAML 文件。您可以在 SyNAP 文档中查看 转换元文件 选项的完整描述。
1. 委派
对于推理,以下委派可用:
default:根据目标硬件自动选择最佳委派。npu:使用 NPU 进行优化推理(SL1680 和 SL1640 的默认值)。gpu:使用 GPU 进行推理(SL1620 的默认值)。cpu:在 CPU 上运行推理。
委派也可以逐层设置。更多信息请参见异构推理。
因此,例如,您的 YAML 中的 delegate 部分应该如下所示:
synap_yaml = """
delegate: npu
"""
2. 输入
这反映了在 Netron 中可见的 YOLOv8s-pose 模型的默认输入的 name、format 和 shape。它定义了一个 NCHW 张量形状 - 1x 图像批次,3x 颜色通道,352x 像素高度,和 640x 像素宽度:
因此,您的 YAML 中的 inputs 部分应该如下所示:
synap_yaml += """
inputs:
- name: images
shape: [1, 3, 352, 640]
scale: 255
format: rgb
"""
3. 输出
目标检测输出格式在模型之间没有标准化,但 SyNAP 支持 retinanet_boxes、tflite_detection、yolov5 和 yolov8 format。landmarks=17 的数量在 YOLOv8s-pose 元文件 中找到,表示基于 COCO 2017 的人体姿态关键点(如眼睛、肩膀、臀部)。w_scale 和 h_scale 参数相对于输入图像缩放边界框和关键点坐标:
synap_yaml += """
outputs:
- format: yolov8 landmarks=17 visibility=1 w_scale=640 h_scale=352
"""
4. 量化
量化仅支持 npu 委派,这意味着它仅支持 SL1680 和 SL1640 处理器。
float16 - 最准确但速度慢(默认)
如果不指定量化,工具包默认将原始的 float32 YOLOv8s-pose 模型编译为 NPU 支持的最接近精度;float16。这会导致模型准确但推理时间非常慢,约为 2900ms。
uint8 - 准确度不够
幸运的是,SyNAP 让我们能够轻松地使用量化来优化速度。我们指定默认量化宽度为 '*': uint8 并提供一组参��考图像以获得代表性的值范围。推理时间为 31ms,但结果为零检测。
int16 - 准确
如果我们切换到 int16,它会给出与 float16 几乎相同的结果,但推理时间几乎是 uint8 的两倍,为 63ms。
混合 uint8 和 int16 - 准确且快速
为了实现速度和准确性之间的更精细权衡,SyNAP 支持混合量化。直观地说,靠近模型输出的层的量化误差对整体模型准确性的影响更大(考虑输入图像上的噪声与输出坐标中的误差)。
因此,在模型开始时使用 uint8 数据,然后在接近末尾的卷积(头部)切换到 int16。当然,其他因素也有助于完善这些选择,您可以在模型量化中了解更多。
令人惊讶的是,这提供了可接受的准确性,同时只比纯 int8 多几毫秒,推理时间为 32ms。
 在 Netron 中查看卷积层
在 Netron 中查看卷积层
synap_yaml += """
quantization:
data_type:
'*': uint8
/model.21/cv2/conv/Conv...: int16
/model.22/cv4.0/cv4.0.0/conv/Conv...: int16
/model.22/cv4.1/cv4.1.0/conv/Conv...: int16
/model.22/Concat_4...: int16
dataset:
- ./*.jpg
"""
现在将元内容写入 synap.yaml 文件
with open('./synap.yaml', 'w') as file:
file.write(synap_yaml)
为 Synaptics Astra 硬件编译模型
使用 synap_convert 运行模型转换,指定 YAML 元文件
synap convert --model yolov8s-pose.onnx --meta synap.yaml --target SL16xx --out-dir converted
在 Astra 上运行模型
上传优化的 YOLOv8 模型
下载您刚刚构建的 model.synap,并将其上传到 Astra 开发板:
adb push ~/Downloads/model-2.synap /home/weston/pose.synap
adb push ~/Downloads/bus.jpg /home/weston/bus.jpg
运行目标检测
adb shell
cd ~weston
synap_cli_od -m pose.synap bus.jpg
推理结果应该在 32ms 左右,太好了!
可视化
要检查人体姿态检测是否具有可接受的准确性,请运行 synap_cli_od 并使用输出图像标志查看渲染的边界框。