模型量化
为了在 NPU 硬件上高效运行模型,必须进行量化。量化包括降低模型权重和激活值的精度,以便可以使用 8 位或 16 位整数值进行计算,而不是计算量更大的 32 位浮点数。量化的一个常见副作用是往往会降低结果的准确性,因此必须谨慎进行。
有三种方式可以对模型进行量化:
- 训练期间:使用 TensorFlow 和 PyTorch 等最新训练框架中提供的量化感知训练功能。这些技术允许在训练阶段本身补偿量化导致的精度降低,从而原则上提供更好的结果。
- 训练后:使用相同的训练框架,将训练好的浮点模型转换为量化模型(例如,将模型转换为量化的
uint8.tflite模型)。这两种方法的优势是它们都能受益于这些框架中量化技术的进步,并且生成的模型仍然是标准模型,因此可以使用标准工具测试和评估量化的效果。 - 使用 SyNAP 工具包转换模型时:这是在训练框架之外量化模型并利用 SyNAP NPU 和工具包特定功能(例如,16 位或混合类型量化)最方便的方式。
为了量化模型,需要确定每一层输出值范围的估计值。这可以通过在样本输入数据集上运行模型并分析每一层的激活值来实现。为了获得良好的量化效果,这些样本输入应该尽可能代表整个预期输入集。例如,对于分类网络,量化数据集应该至少包含每个类别的一个样本。通过为每个类别提供多个样本(例如,在不同的大小、颜色和方向条件下)可以获得更好的量化结果。对于多输入网络,每个输入在每次推理时都必须提供适当的样本。
量化图像尺寸调整
量化数据集中的图像文件不必与输入张量的大小匹配。SyNAP 工具包会自动调整每个图像的大小以适应输入张量。从 SyNAP 2.6.0 开始,这种转换是通过保持图像内容的宽高比来完成的。如果图像和张量具有不同的宽高比,会在输入图像上添加灰色带,以便实际内容不会被扭曲。这对应于运行时通常所做的操作,对于实现可靠的量化很重要。如果相应输入的 format 字符串包含 keep_proportions=0 属性,则不保持宽高比:在这种情况下,图像只是简单地调整大小以填充整个输入张量。
数据归一化
在训练模型时,输入数据通常会被归一化,以便将它们带到更适合训练的范围。通常通过减去数据分布的均值并除以范围(或标准差)将它们带到 [-1, 1] 的范围。每个通道可以使用不同的均值。
为了正确执行量化,重要的是对使用的输入图像或输入样本应用相同的变换。如果不这样做,模型将使用与训练期间(和推理期间)不同的数据分布进行量化,导致结果不佳。这些信息必须在转换元文件的 means 和 scale 字段中指定,并将使用以下公式应用于量化数据集中相应输入的所有输入图像文件:
norm = (in - means[channel]) / scale
对于数据(.npy)文件,不执行此操作,假定它们已经归一化。
此外,在推理时对输入数据也必须应用相同的变换。如果模型在编译时启用了预处理,数据归一化将嵌入到模型中,并在 NPU 内部进行推理时执行。否则,必须在软件中进行数据归一化。Tensor 类提供了一个 assign() 方法,它使用转换元文件中指定的相同 means 和 scale 字段来执行此操作(当归一化嵌入到模型中时,此方法足够智能,可以跳过软件归一化)。
硬件和软件归一化可以互换使用并提供相同的结果。NPU 归一化通常稍快一些,但这需要逐案检查。在软件归一化的情况下,对所有通道使用相同的均值或使用均值为 0 和比例为 1 在某些情况下可以提高性能:例如,如果使用仿射量化,归一化和量化公式(qval = (normalized_in + zero_point) * qscale)可以互为逆运算,从而产生非常高效的直接数据复制。
Tensor::assign() 方法经过优化,以最有效的方式处理每种情况。如果需要,客户可以通过利用 ARM NEON SIMD 指令进一步改进。
量化与精度
如前所述,即使正确执行量化,与原始浮点模型相比,量化模型也往往会带来某种程度的准确性损失。通过将模型量化为 16 位可以减少这种影响,但推理时间会更高。根据经验,将模型量化为 16 位会使推理时间比相同模型量化为 8 位时增加一倍。
引入的量化误差在所有层中并不均匀;某些层的误差可能很小,而其他层的误差可能很大。量化熵是衡量每一层引入误差的指标。
可以通过使用 kl_divergence 算法量化模型来生成 quantization_entropy.txt 文件。此文件将包含网络中每个权重和激活张量的量化熵。它可以用作理解网络在哪里引入误差的指南。每个熵值在 [0, 1] 范围内,越接近 1 表示引入的量化误差越大。kl_divergence 算法是基于这篇论文的迭代算法,试图最小化原始输出和量化输出之间的 Kullback-Leibler 散度。它比标准算法慢,但可以产生更准确的结果。
可以通过将问题层保持在 float16 或使用混合量化将它们量化为 16 位整数来减少问题层的量化误差。
按通道量化
SyNAP 通过指定 perchannel_symmetric_affine 量化方案支持每通道量化。使用此方案时,权重比例按通道计算(每个通道都有自己的比例),而激活值仍然像 asymmetric_affine 量化一样对整个张量使用单一比例和偏置。当权重值分布在不同通道之间变化很大时,为每个通道使用单独的比例可以提供更准确的原始权重近似,从而提高推理准确性。
混合量化
混合量化是 SyNAP 工具包的一个功能,允许在网络转换期间量化时为每一层选择要使用的数据类型。这允许在推理速度和准确性之间实现自定义平衡。
可以采用不同的方法:
- 将整个网络量化为 16 位,只保持输入为 8 位。这提供了可能的最佳准确性,当输入是 8 位图像时很方便,因为它避免了在软件中执行 8 到 16 位转换的需要(注意,如果使用预处理,则不需要这样做,因为它也会处理类型转换)。
- 将大部分网络量化为 8 位,只将问题层量化为
int16或甚至float16。量化熵可以提供指南来选择从 16 位获得更多好处的层。但请注意,每次数据类型变化都需要在其前后添加转换层,所以通常最好避免太多次改变数据类型。 - 将网络的初始部分(主干)量化为
uint8,并将最后部分(头部)切换到int16。当网络输入是 8 位图像时,这通常是一个很好的选择,因为网络通常不应该对输入中的小噪声太敏感。在头部使用 16 位处理允许以更高的精度计算最终结果(例如,边界框),而不会增加太多推理时间。
让我们通过考虑下图中的非常简单的模型来了解这是如何完成的:
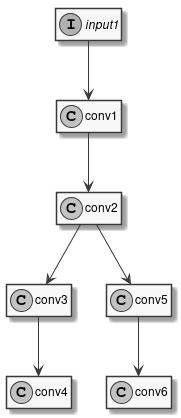
图 4 示例模型
这个模型有一个输入和六个卷积层。我们已经看到了如何使用统一量化来编译它,例如使用 16 位整数:
quantization:
data_type: int16
代替单一类型,data_type 字段可以包含层名称和层类型之间的关联映射。层名称是转换模型中出现的名称,使用 Netron 等免费工具很容易看到它们。因此,前面的示例等同于:
quantization:
data_type:
input1: int16
conv1: int16
conv2: int16
conv3: int16
conv4: int16
conv5: int16
conv6: int16
要执行混合类型量化,只需为每一层选择所需的类型。唯一的限制是 uint8 和 int8 类型不能同时存在。例如,我们可以选择将输入和第一个卷积量化为 8 位,内部卷积量化为 16 位,并保持最终卷积为浮点:
quantization:
data_type:
input1: uint8
conv1: uint8
conv2: int16
conv3: int16
conv4: float16
conv5: int16
conv6: float16
实际模型通常可以有一百多层,所以编写所有层的详尽列表可能会变得混乱和容易出错。为了保持类型规范更简单,可以使用一些快捷方式。首先,可以省略层:未明确列出的层将默认量化为 uint8。此外,层名称规范中的一些特殊约定可以帮助:
INPUTS:这个特殊名称会自动展开为网络所有输入的名称。*@layerId*:以@后缀开头的名称被解释为层ID(见下面的注释)。layername...:后面跟着三个点的名称会展开为模型中指定层之后的所有层的名称(按执行顺序)。当例如我们想对网络头部或整个分支使用相同的数据类型时很有用。'*':展开为所有未明确指定的层的名称。
类型规范按照声明的顺序应用(除了 '*'),所以可以进一步覆盖已经指定的层的类型。
在模型编译期间会应用几个优化,原始网络中的某些层可能会被融合在一起或完全优化掉。对于被优化掉的层,当然不可能指定数据类型。对于融合的层,问题是它们不会有与原始层相同的名称。在这种情况下,可以通过层ID来识别它们:层ID是分配给每个编译层的唯一标识符。这也是在原始模型有模糊或空名称的层时识别层的方便方法。可以在生成的 quantization_info.yaml 或 quantization_entropy.txt 文件中看到编译模型的所有层ID列表。
让我们看几个应用于示例网络的示例。
# 将 input1 量化为 int8,其他所有层量化为 int16
quantization:
data_type:
INPUTS: int8
'*': int16
# 量化为 uint8 但对 conv3、conv4、conv5、conv6 使用 int16
quantization:
data_type:
'*': uint8
conv2...: int16
# 量化为 uint8 但对 conv3、conv4、conv6 使用 int16,对 conv5 使用 float16
quantization:
data_type:
'*': uint8
conv2...: int16
conv5: float16
在上面的两个示例中,规范 '*': uint8 可以省略,因为 uint8 已经是默认值,但有助于使意图更明确。
如果我们为已融合的层指定数据类型,我们将在转换时收到 "Layer name" 错误。在这种情况下,我们必须在 quantization_info.yaml 中查找相应融合层的层ID,并使用上面解释的 "@" 语法。例如,如果在我们示例模型中 conv5 和 conv6 已被融合,如果我们单独指定 conv5 的类型,我们将收到错误。在 quantization_info.yaml 中我们可以找到融合层的 ID,如:@Conv_Conv_5_200_Conv_Conv_6_185:weight。
然后我们可以在元文件中使用这个层 ID 来指定融合层的数据类型:
# 量化为 uint8 但对 conv3、conv4、conv6 使用 int16,对融合的 conv5+conv6 使用 float16
quantization:
data_type:
'*': uint8
conv2...: int16
'@Conv_Conv_5_200_Conv_Conv_6_185': float16